A Systems Biology Approach to Multi-LLM Agent Systems
Research proposal on applying systems biology principles to understand and stabilize multi-agent LLM training dynamics.
Systems Biology offers a productive lens for understanding multi-LLM agent dynamics—treating agents as nodes in regulatory networks enables principled approaches to stability and optimization.
Introduction
Multi-LLM agent systems excel in real-world tasks—e.g., solver–refiner pipelines for math reasoning and coding, multi-agent retrieval-augmented generation (RAG), and collaborative scientific tools. In these systems, role-specialized agents tackle partial subtasks and, through orchestration, collectively solve the end task. For example, in a solver–refiner for math reasoning, a solver proposes candidate solutions, while a refiner selects and improves the most reliable answer.
Current implementations rely heavily on large foundation models and static prompts, which lead to cost inefficiency and prompt-dependent capabilities that limit practical, scalable deployment.
A natural alternative is multi-agent systems built with cost-efficient models, with each agent fine-tuned via SFT or RL for their roles. Training agents independently with verifiable or human-crafted rewards can work in simple settings, but it is brittle and does not scale to complex tasks or many agents. A more scalable approach is to jointly train the network of agents for end-to-end performance (e.g., quality of final answers). In this regime, however, the agents’ learning is coupled and non-stationary, creating multi-body dynamics that make optimization challenging—an important yet underexplored problem.
Why Systems Biology?
Fortunately, Systems Biology offers a productive lens for addressing these challenges. It studies how interacting components—genes, neurons, or species—give rise to stable, functional behavior at the system level. I believe that knowledge and ideas in systems biology can transfer to multi-LLM-agent systems to address challenges and yield impactful research.
Applying a network motif lens to predict and control stability in multi-agent systems.
A methodology inspired by population evolution that leverages agent pools to mitigate training instability and variance.
Project 1: Modeling Multi-Agent Training Dynamics via Network Motifs
Network Motifs with Predictable Dynamics
Feed-forward loops (FFLs) are recurring three-node regulatory patterns (termed motifs) found throughout bacterial and eukaryotic transcription networks. In an FFL, three biological nodes—X (a gene or protein), Y, and Z—form two paths from X to Z: X directly regulates both Y and Z, and Y also regulates Z.
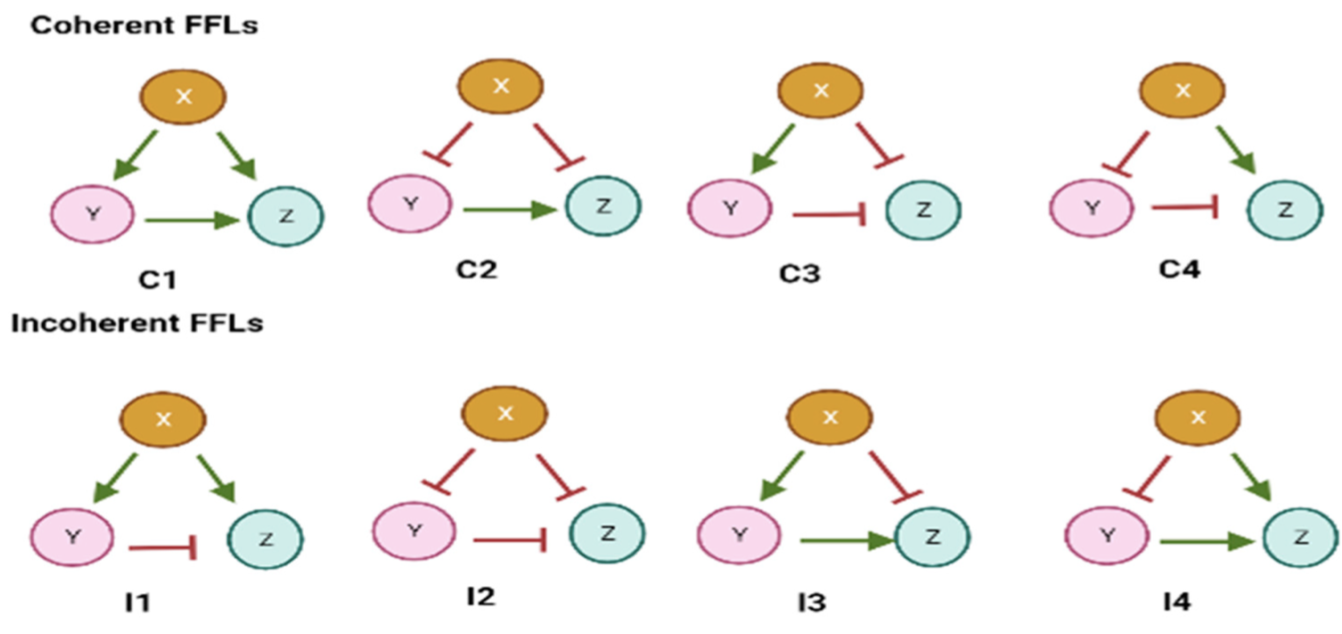
The eight types of feed-forward loops (FFLs). Coherent FFLs (C1–C4) have matching regulatory signs on both paths, enabling persistence detection. Incoherent FFLs (I1–I4) have opposite signs, generating pulse responses and adaptation. Green/red arrows denote activation/repression.
Each node has a time-varying expression level (its activity), and regulation captures how changes in the expression levels of X and Y influence the expression level of Z:
- Coherent FFLs (e.g., C1-FFL: all activating with an AND gate at Z): The motif exhibits sign-sensitive delays and persistence detection, filtering transient noise and stabilizing the output signal.
- Incoherent FFLs (e.g., I1-FFL: X activates both Y and Z, but Y represses Z): The motif generates pulses and adaptation—Z responds rapidly via the direct path, then accumulation of Y suppresses it, creating transient responses that enable fold-change detection and dynamic-range compression.
Multi-LLM-Agent Systems as Regulatory Networks
We map multi-LLM-agent systems to the dynamic regulatory network by treating each agent as a node whose “expression level” is its task competence Ai(t)—the agent’s learned performance for its assigned role at training step t.
Edges between agents represent learning influences:
- Positive (activating) edge X → Y: Improving agent X’s competence accelerates Y’s learning—for example, a better retriever provides richer context that sharpens the reasoner’s learning signal.
- Negative (repressing) edge X ⊣ Y: Improving X throttles Y’s learning activity—for instance, a stricter critic gates the solver’s exploration, reducing its update frequency.
These influences can be implemented and tuned via:
- Dynamic budgets (token/tool quotas)
- Shaped auxiliary credit assignment (interaction-based rewards)
- Gradient coupling (inter-agent regularization)
By treating multi-agent systems as regulatory networks, we can apply established motif-level principles (e.g., stability, adaptation, oscillation) to systematically predict, diagnose, and steer multi-agent training across different topologies and hyperparameters.
Research Questions and Investigation Plan
The central question is: Can the motif framework explain the multi-agent training dynamics—specifically, stability, convergence speed, and adaptation?
We hypothesize that:
- C1-FFLs stabilize training by filtering spurious reward signals
- I1-FFLs accelerate early exploration via rapid transient responses and improve out-of-distribution adaptation, though at higher risk of oscillatory behavior under certain hyperparameter regimes
To test this, we explore simple tasks (e.g., RAG or math QA) where each agent’s performance is reliably quantifiable, examining how motif types and hyperparameters predictably alter training dynamics. We then scale to open-ended tasks (e.g., SWE-bench) to assess whether these patterns hold in more realistic settings.
Project 2: Population-based Methods for Stable Multi-Agent Training
Instability of RL Finetuning
One major challenge of current RL-based LLM finetuning (e.g., PPO or GRPO) is inherent instability. Because policy updates continually shift the training distribution, RL finetuning becomes a moving target with high variance and poor convergence, leading to high costs in finding optimal performance.
In multi-agent setups, this instability compounds dramatically. Each agent’s policy updates simultaneously affect the training signals of all other agents, creating multiple interacting sources of instability. This can trigger cascading failures: one agent’s improvement might destabilize another, leading to oscillating dynamics where agents trade off improvements. Ultimately, the system can become trapped in poor local maxima, failing to achieve its potential performance.
Pool-of-Agents Training
To address this instability, we draw inspiration from how population size shapes drift–selection dynamics in evolution. In large populations, selection is more efficient and genetic drift (stochastic noise) is weaker, producing more reproducible and convergent evolutionary dynamics.
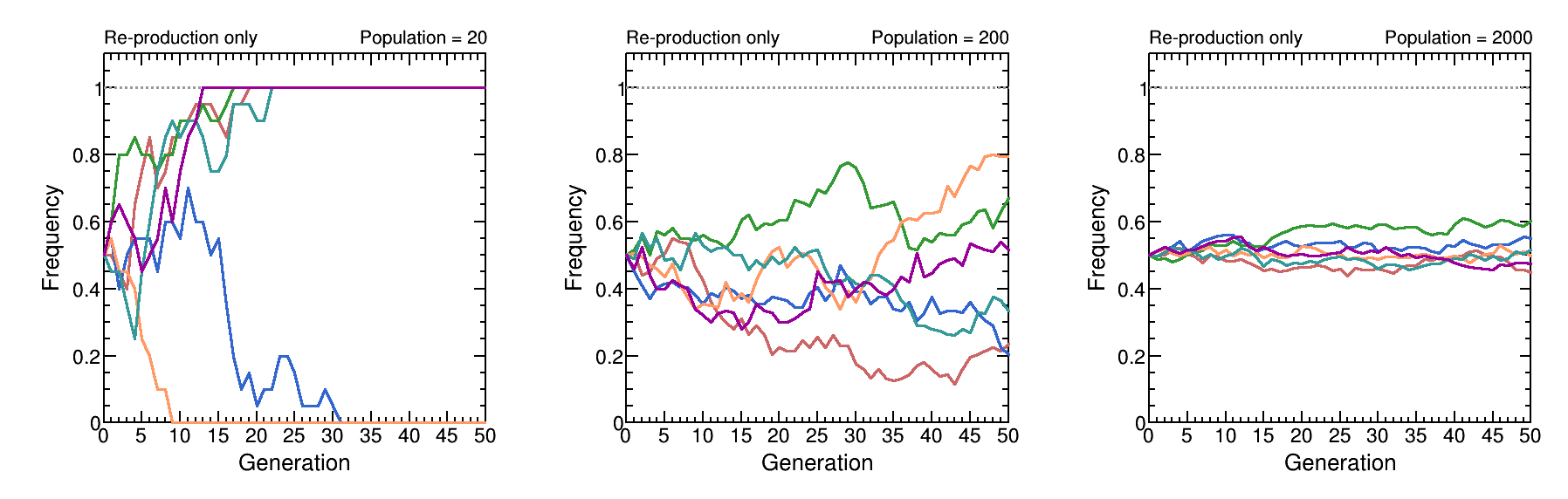
Effect of population size on evolutionary dynamics. With small populations (N=20), genetic drift dominates, causing high variance and rapid fixation. As population size increases (N=200, N=2000), drift weakens and allele frequencies stabilize, demonstrating more predictable evolutionary trajectories.
Adopting this principle, we propose a training method that maintains a Pool-of-Agents for each role, rather than training a single agent per role:
- Pool members perform identical roles but are initialized with slightly different policies via random perturbations
- During each rollout, we sample one member from each pool
- Individual agents can then be updated using standard gradient-based methods, or the pool can be optimized with evolution–strategy-based approaches
Reduced variance through ensemble averaging, more robust exploration of the strategy space, and resistance to cascading failures from individual agent updates.
While maintaining agent pools increases memory and compute costs, these can be mitigated with LoRA or parameter parallelism for efficient deployment.
Research Questions and Investigation Plan
The key question is whether Pool-of-Agents training yields more stable and robust optimization in end-to-end joint training of LLM agents. Specifically, we investigate:
- Whether maintaining agent pools reduces training variance compared with single-agent baselines
- How population size affects the stability–compute trade-off
To address these questions, we will:
- Implement the Pool-of-Agents training framework
- Evaluate across diverse multi-agent tasks (e.g., collaborative dialogue and compositional reasoning)
- Compare against standard RL fine-tuning baselines (PPO, GRPO, etc.)
- Measure variance across random seeds and convergence rate/stability
- Conduct ablation studies on population size
Resources
Full Proposal: Research Statement (PDF)
Related Work:
