Teaching a Protein LLM with Reinforcement Learning: The Gradient Routing Problem
After training a multimodal protein LLM with ESM-3 embeddings and LoRA on 4.89M samples, we applied GRPO reinforcement learning for structure quality prediction. Text-only reaches 0.832 reward while our multimodal MLP pathway stalls at 0.582 – revealing a fundamental gradient routing problem where LoRA and projector gradients cannot flow simultaneously. Here is what we found and what it means for multimodal RL.
When a multimodal protein LLM excels at supervised fine-tuning, why does it struggle with reinforcement learning -- and what does gradient flow tell us about the answer?
The Setup: A Protein LLM That Understands Structure
Over the past month, I have been building a multimodal protein language model. The core idea is simple but ambitious: can we combine a protein structure encoder with a general-purpose language model to create a system that truly understands proteins – not just as sequences of amino acid letters, but as three-dimensional molecular machines with specific structural and functional properties?
The architecture has four components. First, a protein sequence enters ESM-3, a protein foundation model trained by EvolutionaryScale on billions of protein sequences. ESM-3 produces rich 1536-dimensional embeddings that capture structural, evolutionary, and functional information about each residue. These embeddings then pass through an attention pooling layer that compresses variable-length protein representations into a fixed set of 32 tokens, followed by a two-layer MLP projector (1536 to 5120 to 2560) that maps them into the LLM’s input space. Finally, these 32 projected tokens are injected into Qwen3-8B-Instruct alongside the text prompt, and the LLM generates its response.

We compare this multimodal “MLP” pathway against a simpler text-only baseline where the raw amino acid sequence is directly tokenized as text (wrapped in <protein>...</protein> tags) and fed to the LLM. No encoder, no projector – just the LLM seeing letters like MKTLLILAVL as regular text tokens. This comparison lets us isolate the contribution of ESM-3’s structural embeddings.
The entire system is trained with LoRA (rank 8, applied to all linear layers in the LLM), keeping the base Qwen3-8B weights frozen and ESM-3 permanently frozen. The trainable parameters are the LoRA adapters (~2M params), the attention pooling (~9.5M), and the MLP projector (~21M) – about 32.5M parameters in total, a fraction of the 8 billion in the base LLM.
The Data: 4.89 Million Protein Instructions
Before we could train anything, we needed data. We assembled a dataset from six protein-focused sources, covering four categories of tasks:
- Protein description and function – explaining what a protein does based on its sequence
- Structure prediction and analysis – discussing 3D structure, folding, and stability
- Interaction and binding – protein-protein and protein-ligand interactions
- Design and engineering – rational design and mutation effects
After preprocessing, sampling, and quality filtering, the final combined dataset contained 4.89 million instruction-response pairs. Each example follows the Qwen3 chat template format with a protein-expert system prompt, the protein sequence (either as ESM-3 embeddings or raw text), and a question-answer pair.
SFT Results: The MLP Advantage
The supervised fine-tuning results were unambiguous. Over 9750 training steps on 8x H100 GPUs, the ESM3+MLP model converged to an eval_loss of 0.361 – a 70.1% improvement over the text-only baseline at 1.207.
| Metric | ESM3+MLP | Text-Only | MLP Advantage |
|---|---|---|---|
| Best eval_loss | 0.361 (step 9750) | 1.207 (step 8000) | 70.1% lower |
| Final token_avg_loss | 0.438 | 1.643 | 73.4% lower |
| Gradient norm (mean) | 0.627 | 2.365 | 3.8x lower |
| Convergence | Stable plateau | Slight overfitting | – |
These numbers tell a clear story. The MLP model benefits enormously from ESM-3’s structural embeddings. Where the text-only model must infer structural information from raw amino acid letters – an extremely lossy representation – the MLP model receives pre-computed structural features that ESM-3 learned from billions of protein sequences.
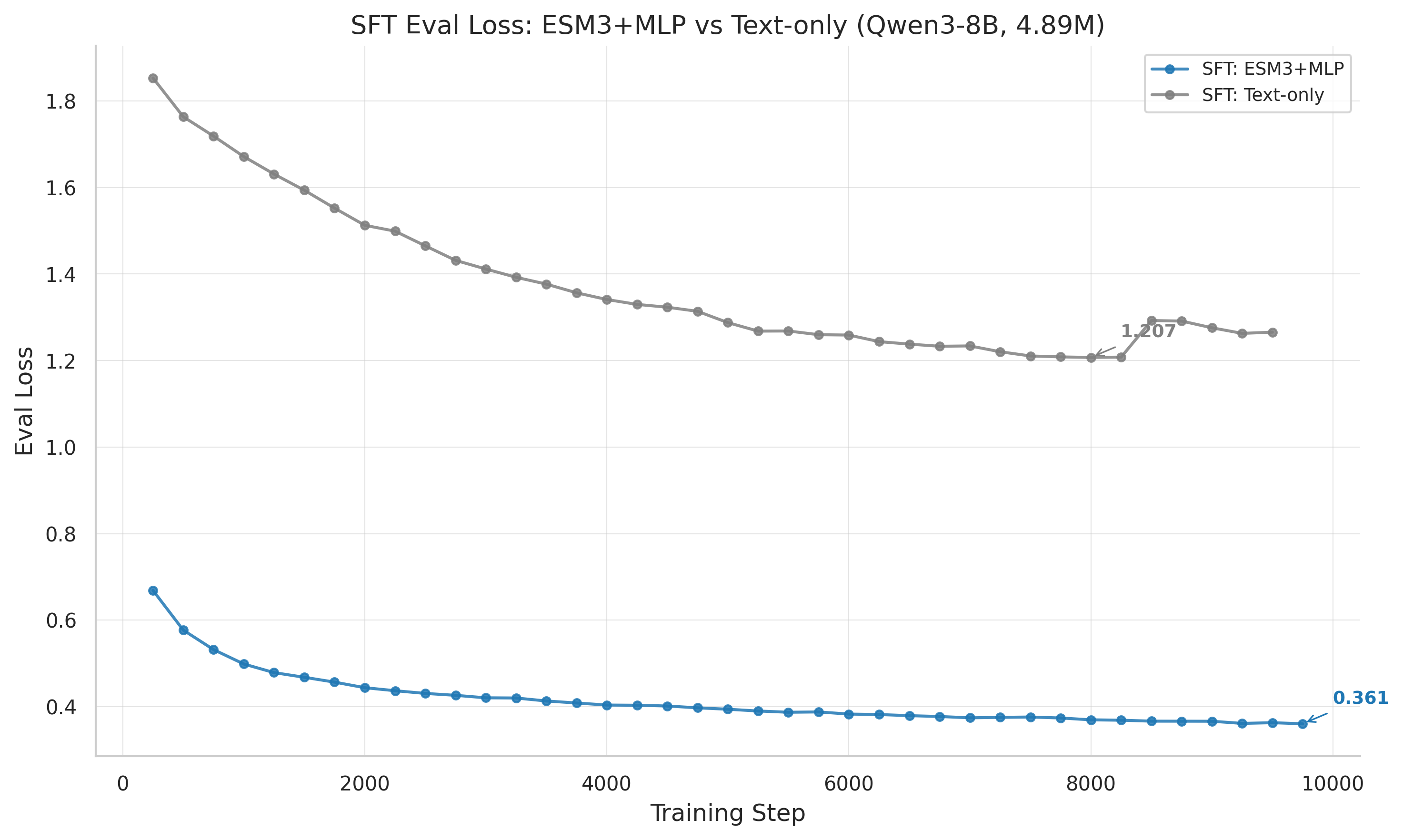
The convergence dynamics are also revealing. The MLP model’s eval_loss decreases smoothly and monotonically, with the last five evaluation checkpoints ranging only 0.006 (from 0.361 to 0.367). This is a cleanly converged model. The text-only model, by contrast, reaches its best eval_loss at step 8000 (1.207) but then begins overfitting, degrading to 1.266 by step 9500. The overfitting window spans about 1500 steps, suggesting that with early stopping, step 8000 is the best text checkpoint.
The gradient norms reinforce this picture. The MLP model maintains a mean gradient norm of 0.627 with standard deviation 0.326 – smooth, well-behaved optimization. The text-only model runs at 2.365 mean gradient norm with 0.647 standard deviation. The 3.8x higher gradients in text-only reflect a harder optimization landscape where the model must work much harder to extract useful signal from raw sequence tokens.
We also attempted a third pathway – the Perceiver Resampler – which replaces both pooling and MLP with a cross-attention mechanism (29.4M parameters, comparable to MLP’s 30.5M). Unfortunately, this experiment failed to launch; the log directory was created but remained empty. The perceiver pathway remains untested at the 4.89M scale, and retrying it is on our priority list.
From Imitation to Reasoning: Enter GRPO
SFT teaches the model to produce outputs that look like the training data. But can we go further? Can we teach the model to reason about protein structure using reinforcement learning?
Group Relative Policy Optimization (GRPO) is our RL method of choice. For each prompt, the model generates a group of completions (typically 8 or 16). A reward function scores each completion, and the model updates toward the better-rewarded outputs using a policy gradient. The key innovation of GRPO over standard RLHF is that rewards are normalized within each group, producing relative advantages rather than absolute scores.
For the structure quality task, we designed a multi-component reward function that evaluates the model’s ability to assess protein structural quality:
- Quality alignment (weight 0.4): Does the model correctly categorize structural quality based on the ESMFold-computed pLDDT score?
- Numerical accuracy (weight 0.3): How close is the model’s predicted pLDDT to the actual value?
- Category match (weight 0.3): Does the predicted quality category (high/medium/low/very low) match the ground truth?
- Format bonus (0.1): Does the output follow the expected JSON format?
The training data consists of 5878 protein sequences (filtered from 10K by removing proteins longer than 512 amino acids). Each protein is folded by ESMFold to produce ground-truth structural quality metrics, and the model must learn to predict these metrics from the protein sequence.
We ran 13 GRPO experiments over three days, systematically testing different configurations: MLP vs text-only approaches, different training durations (3 to 10 epochs), frozen vs unfrozen multimodal parameters, focal reward weighting, and classification-based task reformulations.
The Reversal: Text Wins at RL
Then came the surprise. When we applied GRPO to both SFT checkpoints, the rankings completely inverted.
The text-only model, starting from its eval_loss=1.207 SFT checkpoint (the worse SFT model), rapidly learned to generate well-formatted, accurate structure quality assessments. Over training, its mean reward climbed to 0.832, with near-perfect format compliance (format bonus 0.099 out of 0.1) and remarkably well-calibrated pLDDT predictions (79.1 predicted vs 79.7 actual – within 1% of ground truth).
The MLP model, despite its dramatically superior SFT performance (eval_loss 0.361), stalled at a much lower reward. Its standard GRPO configuration reached only 0.582 mean reward, with format compliance stuck at 65% and systematically underestimating pLDDT (67.9 predicted vs 79.7 actual – off by 15%).
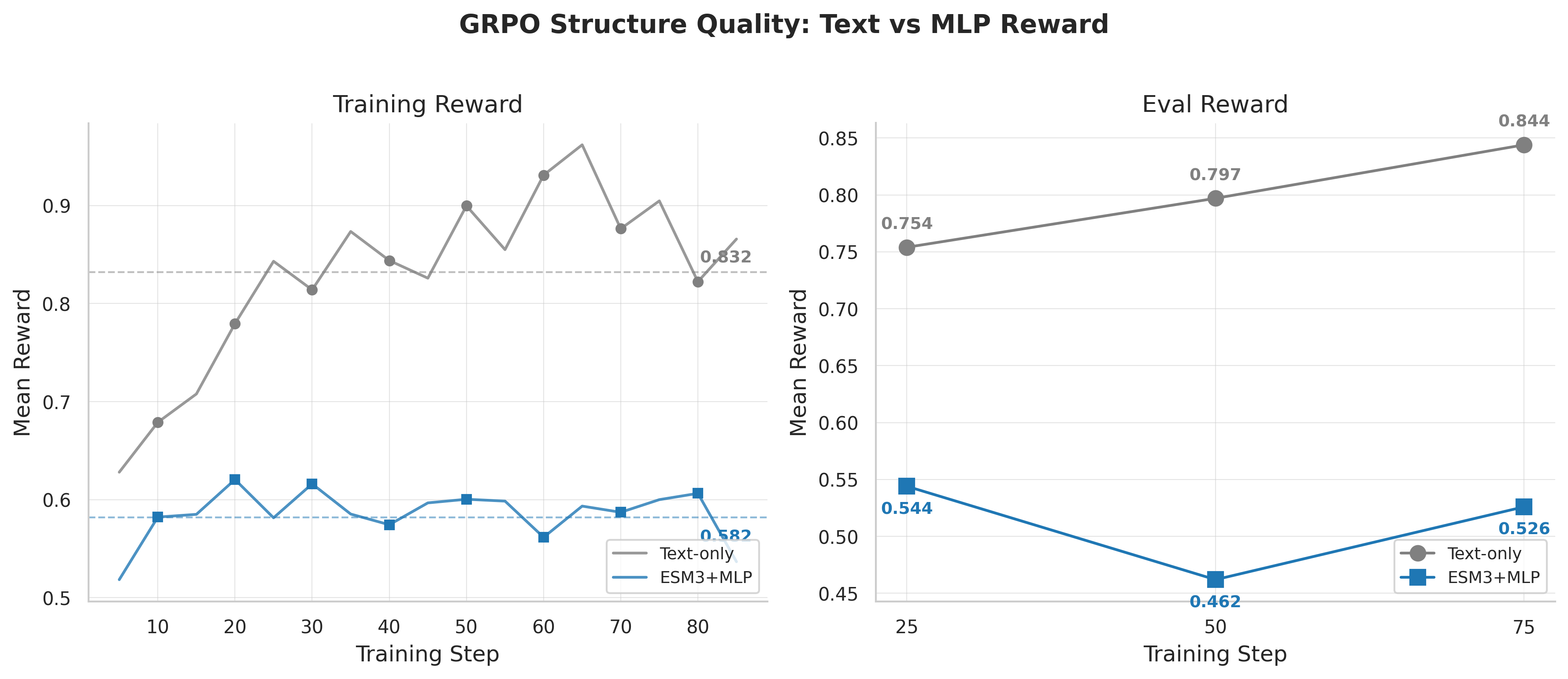
Let me emphasize how counterintuitive this is. The model that better understands proteins (as measured by SFT loss) is worse at learning to reason about them through RL. The model with cruder protein representations (raw text tokens) learns faster and reaches higher reward.
Diagnosing the Problem: Follow the Gradients
To understand why, I looked at the gradient norms. In training, gradient norms tell you which parameters are actually receiving learning signal. If a parameter group has zero gradient, it is not learning – regardless of how much compute you spend.
The gradient norms told a striking story. In the MLP model during structure quality GRPO:
- LoRA gradients: effectively zero – the LLM’s adapter weights received no learning signal
- Multimodal gradients: 0.247 – only the projector updated
For contrast, in a different GRPO task (ProteinLM benchmark), the pattern reversed:
- LoRA gradients: 0.826 – the LLM adapters were actively learning
- Multimodal gradients: 0.0 – the projector was completely frozen
The text-only model, with its single gradient pathway, had no such problem:
- LoRA gradients: 0.476-0.493 – healthy, consistent signal
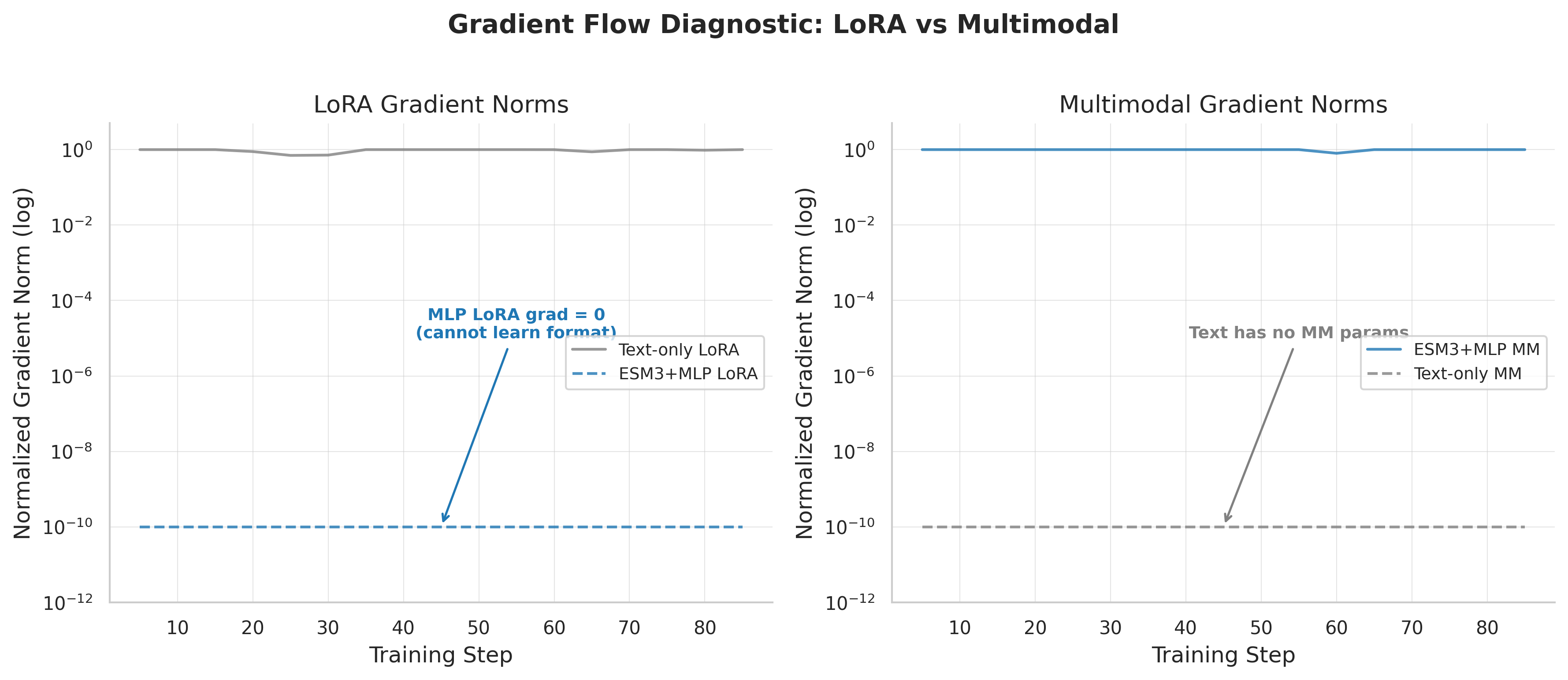
I call this the gradient routing problem: in the multimodal model, gradients flow exclusively to one subsystem during GRPO, completely starving the other. The “winner” appears to depend on the reward function and task characteristics, but the result is always the same – half the model cannot learn.
This is fundamentally different from SFT. During supervised fine-tuning, the next-token prediction loss provides a dense, per-token gradient signal that flows through the entire computational graph. Both the projector and LoRA adapters receive meaningful gradients because every token prediction depends on both the protein embeddings (flowing through the projector) and the language modeling capability (captured by LoRA). The loss is computed on hundreds of tokens per example, providing rich gradient information.
During GRPO, the signal is sparse. The reward is a single scalar computed on the entire completion. The policy gradient must propagate this scalar backward through the generation process, and somewhere in this chain, the signal becomes “winner-take-all.” The parameter group that provides the steepest local descent captures the gradient signal, leaving the other group in a flat region of the loss landscape.
The Fix (Partial): Freeze and Focus
If the gradient routing problem prevents simultaneous updates, what happens when we eliminate one pathway entirely?
We ran a “frozen-MM” experiment: freeze the multimodal projector completely and only update LoRA weights during GRPO. This forces all gradient signal through the LoRA pathway, removing the competition.
The results were encouraging:
| Configuration | Mean Reward | Format Bonus | LoRA Grad | MM Grad |
|---|---|---|---|---|
| Text-only (standard) | 0.832 | 0.099 | 0.476 | 0.0 |
| MLP frozen-MM | 0.774 | 0.095 | 0.071 | 0.0 |
| MLP frozen-MM + focal | 0.725 | 0.095 | 0.119 | 0.0 |
| MLP standard | 0.582 | 0.065 | ~0 | 0.247 |
Freezing the projector raised MLP GRPO reward from 0.582 to 0.774 – a 33% improvement. Format compliance jumped from 65% to 95%. This confirms that the gradient routing problem was the primary bottleneck: once LoRA can actually receive gradients, the MLP model learns effectively.
But text-only still outperforms at 0.832. The LoRA gradients in frozen-MM MLP (0.071-0.119) are noticeably smaller than text-only (0.476). Even with the projector frozen, its presence in the forward pass creates a partial information bottleneck. The LoRA adapters must learn through a compressed 32-token protein representation, while the text-only model’s LoRA can directly interact with every amino acid token in the sequence.
We also tried adding focal reward weighting, which upweights harder examples. This actually slightly hurt performance (0.725 vs 0.774 for frozen-MM alone), possibly because the focal weighting destabilizes the already-small LoRA gradients.
The Reward Breakdown: Component-Level Analysis
Breaking down the reward into components reveals exactly where each model excels and struggles.
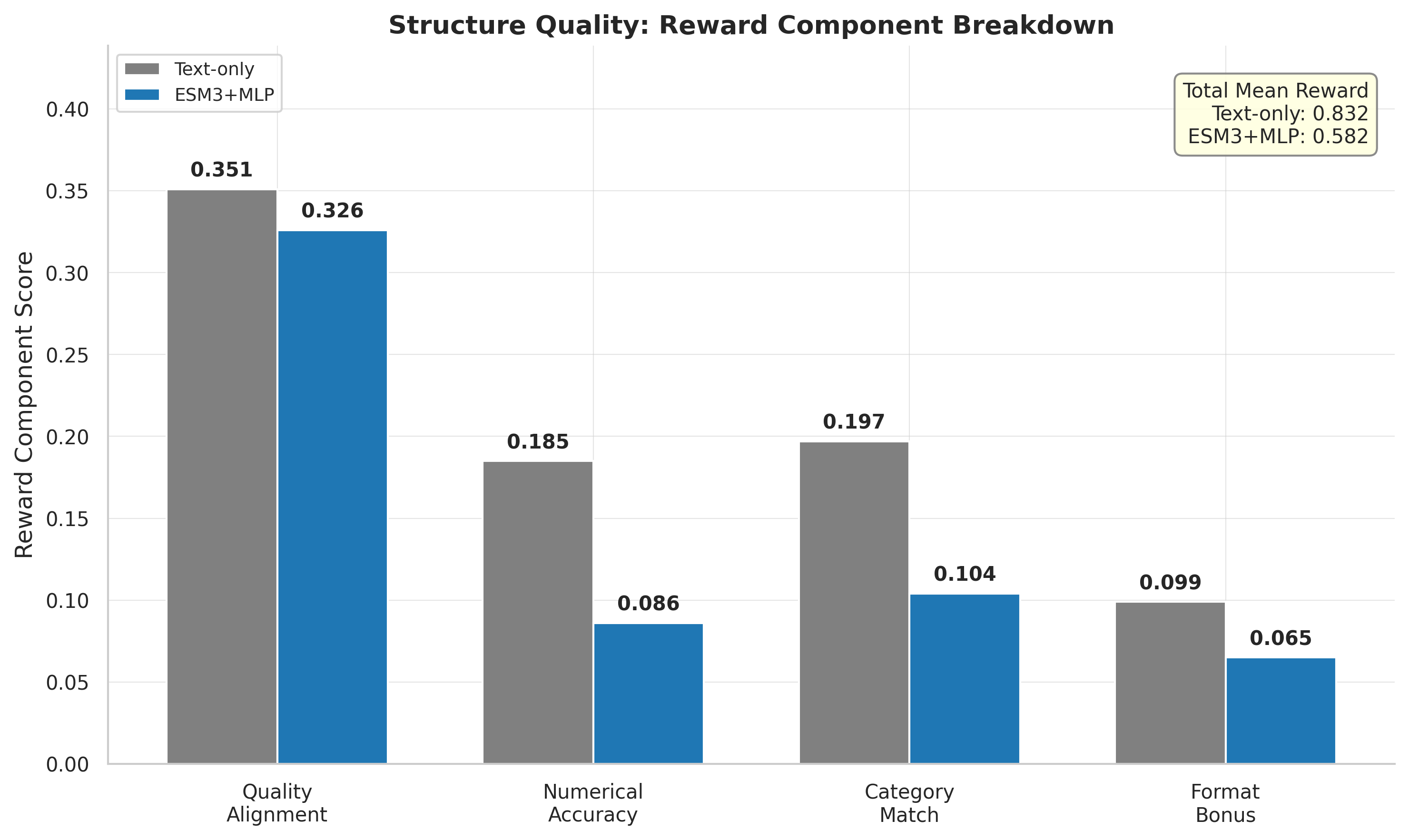
The text-only model outperforms across all four components. The biggest gaps are in numerical accuracy (text: 0.185, standard MLP: 0.086, frozen-MM MLP: 0.169) and category match (text: 0.197, standard MLP: 0.104, frozen-MM MLP: 0.164). Quality alignment is closer (text: 0.351, standard MLP: 0.326, frozen-MM MLP: 0.347).
One particularly revealing detail is pLDDT calibration. The actual mean pLDDT in the evaluation set is 79.7. The text-only model predicts 79.1 – remarkably close. The frozen-MM model overestimates at 85.1, while the standard MLP model underestimates at 67.9. This bidirectional miscalibration suggests that the projector embeddings contain strong pLDDT-relevant signal, but the GRPO training process fails to calibrate it properly. When the projector is frozen, its fixed embeddings anchor the LLM toward high-quality predictions; when unfrozen, the projector drifts in the absence of LoRA co-adaptation.
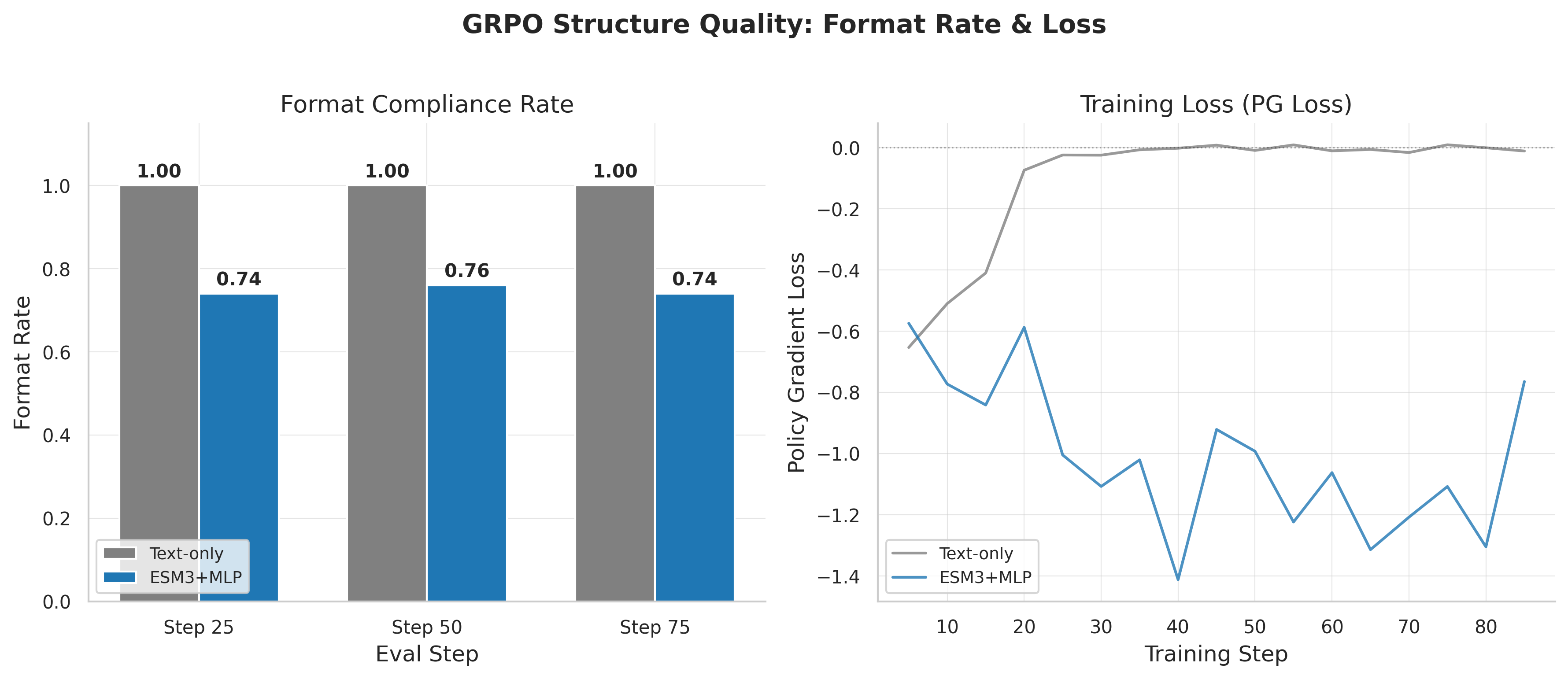
The format compliance story is particularly clear. The text-only model achieves essentially 100% format compliance from early in training. The standard MLP model stays stuck at 74-76%. The frozen-MM model recovers to ~95% compliance. Format compliance is entirely a function of LoRA learning – the LLM needs to learn the JSON output format – and when LoRA gradients are zero, format never improves.
The ProteinLM Benchmark: A Negative Result
We also tried GRPO on a second task: the ProteinLM benchmark, a curated set of 849 protein understanding questions with multiple-choice answers. The reward function scored the model on answer accuracy.
This was a clear negative result. Neither 3-epoch training (39 steps, final reward 0.695) nor 10-epoch training (130 steps, final reward 0.676) showed any reward improvement. The reward oscillated noisily around 0.68 throughout training with no discernible trend.
The root cause was different from structure quality but equally instructive. Here, 37-42% of groups had zero reward standard deviation, meaning the model generated nearly identical completions within each group. When all completions in a group are the same, the advantages are all zero, and no learning occurs. Nearly half the compute was wasted on groups that produced zero gradient signal.
Interestingly, the gradient routing was reversed compared to structure quality: LoRA received healthy gradients (mean 0.8) while multimodal gradients were exactly zero. The task’s small dataset (849 samples) and the high zero-std fraction suggest it simply does not provide enough diversity of training signal for GRPO to gain traction.
What This Means for Multimodal RL
The gradient routing problem reveals something fundamental about the difference between supervised and reinforcement learning in multimodal architectures.
In SFT, the loss landscape is smooth and well-conditioned. Every token contributes to the loss, and the chain rule distributes gradients naturally through both the projector and LoRA. The two parameter groups cooperate: the projector provides better protein representations, and LoRA learns to use them. This is classical multi-task cooperation.
In GRPO, the optimization landscape is fundamentally different. The reward is a single scalar for an entire completion. The policy gradient amplifies differences between better and worse completions, but this sparse signal must compete for bandwidth between two parameter groups. The result is a “winner-take-all” dynamic that resembles the gradient conflicts studied in multi-task learning (Sener & Koltun, 2018; Yu et al., 2020).
This connects to broader findings in the multimodal RL literature. Vision-language models like Flamingo and LLaVA also struggle with RL fine-tuning, often requiring careful stage-wise training. The gradient routing problem may be a general phenomenon in multimodal RL, not specific to protein models.
What is Next
Three directions follow from these findings:
1. Two-stage GRPO. First train with frozen multimodal parameters to teach format compliance and basic reward structure through LoRA. Then unfreeze the projector for fine-grained structural learning. This sequences the gradient pathways rather than forcing them to compete. The frozen-MM results (0.774 reward) suggest this first stage could establish a strong foundation.
2. Gradient balancing. Explicitly balance the gradient norms between LoRA and multimodal parameters using methods like GradNorm (Chen et al., 2018) or PCGrad (Yu et al., 2020). The mutual exclusion we observe is exactly the kind of gradient conflict these methods were designed to address. We could also try simply scaling the multimodal learning rate relative to LoRA during GRPO.
3. The Perceiver pathway. Our Perceiver Resampler SFT failed to launch and remains untested. With 29.4M parameters (comparable to MLP’s 30.5M), the Perceiver uses cross-attention rather than concatenation to integrate protein information. This architectural difference may produce different gradient routing behavior during GRPO, potentially avoiding the winner-take-all dynamic.
The central paradox remains: our best SFT model (MLP, eval_loss 0.361) produces our worst GRPO learner (reward 0.582), while our weaker SFT model (text-only, eval_loss 1.207) produces our best GRPO learner (reward 0.832). This SFT-RL inversion is the defining challenge for the next phase of this project, and resolving it could teach us something important about how multimodal systems learn from sparse reward signals.
This analysis covers 4 SFT and 13 GRPO experiments run between March 6-13, 2026, on 8x H100 GPUs. All models use Qwen3-8B-Instruct-2507 with LoRA (r=8). The combined SFT dataset contains 4.89M instruction-response pairs from six protein data sources. GRPO structure quality data contains 5878 training samples with ESMFold-based rewards. All loss values reported as eval_loss unless otherwise noted; training loss uses token_avg_loss (true per-token average, not HF Trainer’s running average).
